人在做自己喜欢的事情时,时光总是过得很快。不知不觉到公司已经两年多了,在这两年的时间里,我做了很多“有趣又有用”的事情,其中最让我有成就感的有两件事:
第一,从0到1搭建了一套基于K8s的机器学习平台,高效、稳定、好用,用户访问量翻了30多倍;
第二,通过坚持不懈的资源优化,使整体资源利用率从30%左右提升到65%+,为公司节省了150+台高配机器,经济价值超过500万¥。
今天就和大家分享一下在资源优化方面的一些心路历程。
1. 非技术方案
1.1 机器梳理
我刚到公司的时候,机器学习平台的机器使用非常混乱。
- 有多少台机器?不知道!
- 都是哪些机器?不知道!
- 这些机器都在做什么?不知道!
- 这些机器都是什么配置?不知道!
- 哪些机器是其他组负责的?不知道!
所以,我就找运维协助,把我们所负责的机器梳理了一遍,最终梳理出483台机器,并确认每台机器的配置,同时和其它组确认好机器的归属问题,然后整理成一个表格,标记好机器的各项重要指标。在这个过程中,我找到了19台属于我们,却一直未被使用,未被加入到服务树(我们公司的运维平台)的“野机器”。
1.2 集群合并
我到公司时,机器学习平台的容器编排工具是Marathon+Mesos,每个Mesos集群由3个master节点和若干个slave节点组成,由于机器学习任务都比较繁重,为了master节点的稳定,我们是不往master节点上调度任务的。所以,master节点几乎始终处于空闲状态。
经过我多次确认,我们的Mesos 集群居然多达7个(还不包括帮其他组搭建的6个 Mesos 集群),也就是说有21台机器只作为master节点,几乎始终处于空闲状态。并且,这7个Mesos集群给我们带来了巨大的运维负担,消耗了我们大量的工作时间和非工作时间。
于是,在我接管之后,就把这些集群做了一系列合并,最终合并成一个集群,并且通过自动化运维,使集群的稳定性提升到了99.99%,这样就节省出18台机器,也使我们从人肉运维的泥淖中解脱出来。
1.3 机器内存扩容
机器学习任务由于要加载大量的样本和模型数据到内存中,从而加快训练速度,所以,内存一直是机器学习任务的瓶颈。于是,我想:是不是可以通过扩容机器上的内存,来减少每组训练任务所需机器数量呢?
这是一个显而易见的道理,为什么之前就没有人想到呢?我想,应该是司空见惯了,反而不会想着去改变。
于是,我联合算法和运维同学,由运维同学负责扩容内存并测试兼容性,算法同学来验证训练任务在大内存机器上运行是否正常。最终,我的想法完全可行。
于是,我们通过一条几百元的内存条,就实现了一台价值3~4万机器的效果,这给我们带来了巨大的收益。
1.4 GPU置换为CPU
之前,TensorFlow 是我们的主流训练框架,很多排序和召回的算法同学都喜欢用 GPU 机器来提升一下训练速度,但由于没有GPU指标监控功能,我们并不知道这86台 GPU 机器的显卡使用率。后来,我想办法开发了一套 GPU 监控程序,这才发现原来80%以上显卡使用率连 1% 都不到,甚至部分完全空闲。很多算法同学使用 GPU 只是图个心理安慰而已,其实并没有达到预期的效果,反而造成了很多真正需要 GPU 资源的算法同学没有资源可用。于是,我先是通过GPU共享技术(详见2.8),使一张显卡达到了之前两倍的效果。
并且,今年以来,随着算法团队人员发生了一系列重大调整,主流训练框架也从 TensorFlow 变成了 PaddlePaddle,而 PaddlePaddle 是不需要使用GPU资源的。于是,使用 GPU 资源就变得更加没有必要。我就开始推动算法同学把训练任务从 GPU 机器迁移到 CPU机器,然后把 GPU 机器交给更依赖 GPU 的图像识别、视频识别、NLP等训练任务去使用,这样就达到了双赢的效果。
最终,我们在每增加 CPU 机器的前提下,将 GPU 机器数量从 86 台压缩到 28 台。
1.5 规范资源申请流程
在此之前,算法同学对资源是使用是完全凭个人感觉,想用多少就用多少,完全不做限制。很多实验动辄占用20台机器,结果就造成483台机器最多只能同时支持50组实验,而整体资源利用率只有30%左右。
于是,我在建立起 K8s 集群之后,就建立了一套完善的资源监控反馈体系(详见2.5),通过监控训练任务近7天的资源使用情况,来限制下次重启时可用资源量。如果有特殊需求需要超过限制的,需要走工单进行审批。
功能上线后,很多同学就主动降低了资源申请量,于是资源使用率就逐步开始提升了。

资源申请流程
1.6 任务分级
我们的训练任务大致分为两类,一类是探索型实验,一类是线上实验,其中线上实验由根据所承载流量比例分为小流量实验和主流量实验。顾名思义,按重要程度来排序,主流量实验 > 小流量实验 > 探索型实验。
于是,我就把任务按照重要程度划分成三个等级,优先级越高,可申请资源的buffer越多,QoS也越高。这样就达到了节省资源和保证任务稳定性的双重目标。
1.7 资源分组
每个人都想尽可能多启动一些实验,从而更快地验证模型效果,但资源是有限的,如果一部分人占用资源太多,其他人就会陷入无资源可以的境地,这就造成经常需要我们出面去协调资源。所以,在各组之间实行资源隔离就显得很有必要。
于是,我们就按照业务对人员进行分组,并与各组负责人开会确定各组所需资源数量,然后按比例给各组分配资源数量。如果某组资源耗尽,可以通过组内线下协调的方式腾挪资源,我们也就获得了解放。
2. 技术方案
2.1 Merge调度
机器学习训练任务每10分钟会生成一个增量模型,这个增量模型(inc)中只包含近10分钟样本训练的结果,模型文件很小。每隔10小时左右会把近段时间的所有增量模型与之前的全量模型(full)进行合并(Merge)而生成新的全量模型。
当训练生成full模型时(Merge),资源占用率会明显上升,此时训练出错的风险较高。如果将Merge单独运行,则可以明显降低出错风险,并保证资源占用率的平缓和稳定。所以,需要将所有训练的Merge单独运行和调度。
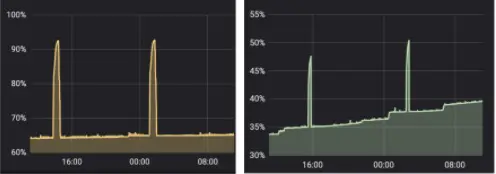
生成full模型时资源占用飙升
之前的做法是给这些 Merge 任务单独搭建了一个有40台机器的 Mesos 集群,然后由训练任务每隔10小时自行调度起其对应的 Merge。由于各个任务互相独立,这就导致经常会有多个 Merge 任务被同时启动的情况出现,因为争抢有限的机器资源而发生死锁,经常需要人工去干预。
于是,我重新设计了一套 Merge 调度方案:
- 首先,停止训练任务自行启动 Merge,改由 Alpha (我们的机器学习管理平台)来统一定时调度。
- 其次,设置排队机制,根据一些策略计算出每个 Merge 任务的权重,权重超过阈值的可以进入队列,权重越高,越靠近队列头部。
- 再者,定时从队列头部取出 Merge 任务并尝试启动。如果当前资源不足,就停止启动并放回队列头部,如果资源充足,就真正启动Merge任务。
- 最后,定时检查正在运行的 Merge 的运行状态,如果 full 模型已经生成,或者运行超时,则强行停止 Merge 任务,以防任务卡死而无法正常释放资源。
整个过程如下图所示:
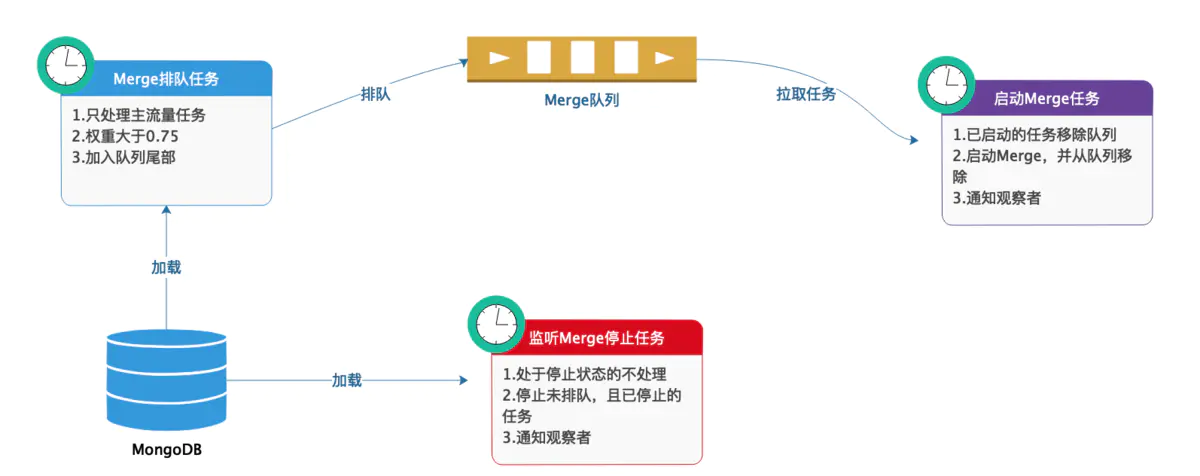
Merge调度
这样就彻底解决了因资源争抢而造成的死锁问题。最终,只用18台机器就实现了 Merge 任务的正常运行。下图是优化后的效果,可以看到inc和full模型的延迟都非常稳定,整个调度过程完全无需人工干预。
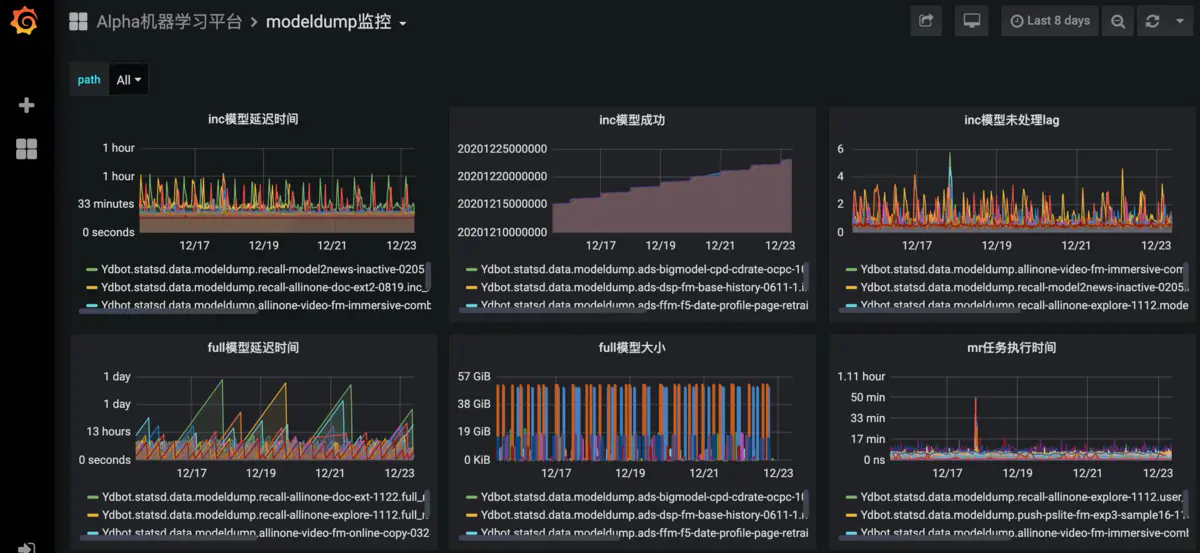
优化效果
2.2 使用K8s替代Mesos
Mesos虽然也是一个优秀的容器编排工具,但和 K8s 比起来功能还是太显单薄,特别是在任务调度方面短板很明显。于是,我通过建设 基于K8s的机器学习平台搭建(一) 并逐步通过 “绞杀者模式”实现任务从Mesos向K8s迁移 使我们具备了更稳定的基础架构和更灵活的任务调度能力,这给我们后来的一系列工作带来了巨大的便利。
2.3 真正容器化
在此之前,虽然我们也在使用 Docker 容器化技术,也在使用 Mesos 容器编排工具,但使用的方式并不能真正发挥容器化技术的优势。由于网络模式采用的是host模式(参考 Docker四种网络模式),且所有任务都使用相同的端口,因端口冲突而导致同一台机器上无法部署多个任务。
于是,我在任务迁移到 K8s 的同时,借助Istio Ingress + 随机端口相结合的方式(如下图所示)彻底解决了端口冲突的问题,从而实现真正的容器化,使一台机器上运行多个任务变成可能。再结合我们的一系列资源优化手段,使我们的整体资源利用率提升了30%+。
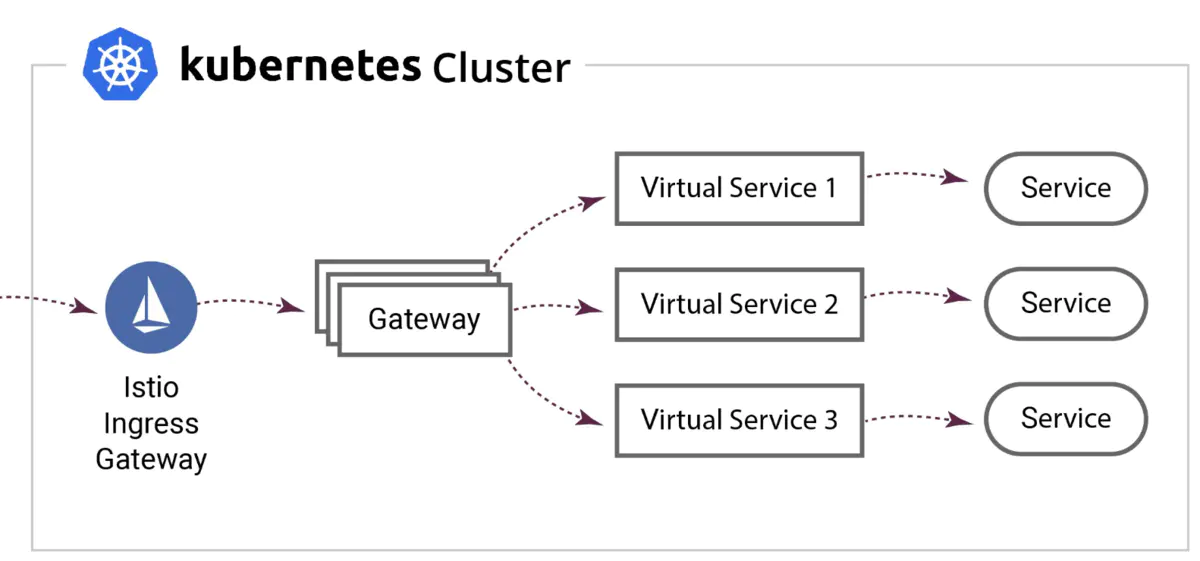
Istio Ingress机制
2.4 资源限额
上面我介绍过,之前算法同学对资源是使用是完全凭个人感觉,想用多少就用多少,完全不做限制。这就导致很多实验资源占用量远超实际使用量。
为了实现资源的精确分配,我们通过 Prometheus 来监控各项任务的实际资源使用情况,保留近7天的数据。Alpha定期从 Prometheus 读取这些数据,进行聚合后,保存到数据库中。下次用户重启任务时,我们就根据此来限制任务可申请资源量。当然,为了保证任务的稳定运行,我们会给任务预留出一些buffer。

资源限额
2.5 实验资源利用率排名
安于现状是很多人的天性,想要算法同学主动去配合节省资源存在一定的难度。于是,我们就开发了实验资源利用率排名功能,并定期在周会上通报,从而使算法同学逐步养成起了资源优化的习惯。
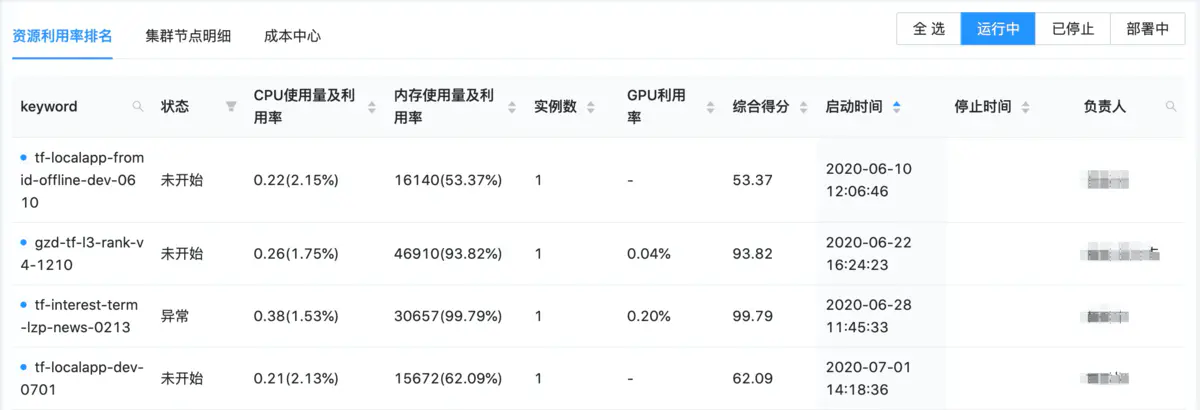
资源利用率排名
2.6 个人成本中心
在对实验进行资源利用率排名的同时,我们也将资源使用情况细分到了个人粒度,对个人所有资源的成本折算成现金并排名,并每周发送邮件报表。这样,领导们就能看到每个人所消耗的成本,再结合其所创造的价值,从而无形中给了算法同学优化资源的压力。
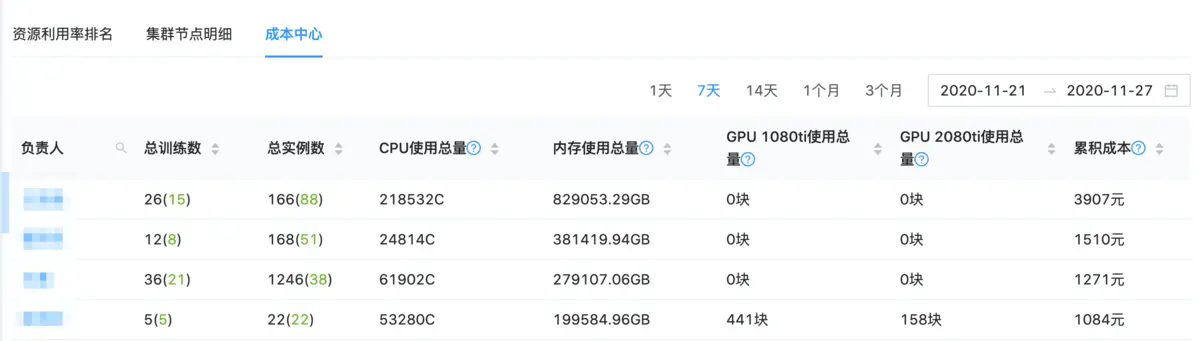
个人成本中心
2.7 GPU共享技术
通过GPU共享技术(详见 Kubernetes GPU 共享技术调研 和 Kubernetes GPU共享实践)我们实现了显卡的一卡多用,GPU使用率提升了80%。
2.8 调度方案升级
K8s默认的调度插件是kube-scheduler, kube-scheduler默认会把任务调度到资源最空闲的机器上,而机器学习任务大都是重型任务,不能有效地实现填补“资源碎片”。
于是,我们使用华为开源的Volcano替代了kube-scheduler,从而实现了更合理的任务调度方式。
Volcano 首先要解决的问题就是Gang Scheduling的问题,即一组容器要么都成功,要么都别调度。这个是最基本的用来解决资源死锁的问题,可以很好的提高集群资源利用率(在高业务负载时)。除此之外,它还提供了多种调度算法,例如priority优先级,DRF(dominant resource fairness), binpack等。 我们今天就是挖一挖Volcano内部的各种调度算法实现。
- Gang Scheduling
这种调度算法,首先就是有’组’的概念,调度结果成功与否,只关注整一’组’容器。
具体算法是,先遍历各个容器组(代码里面称为Job),然后模拟调度这一组容器中的每个容器(代码里面称为Task)。最后判断这一组容器可调度容器数是否大于最小能接受底限,可以的话就真的往节点调度(代码里面称为Bind节点)。
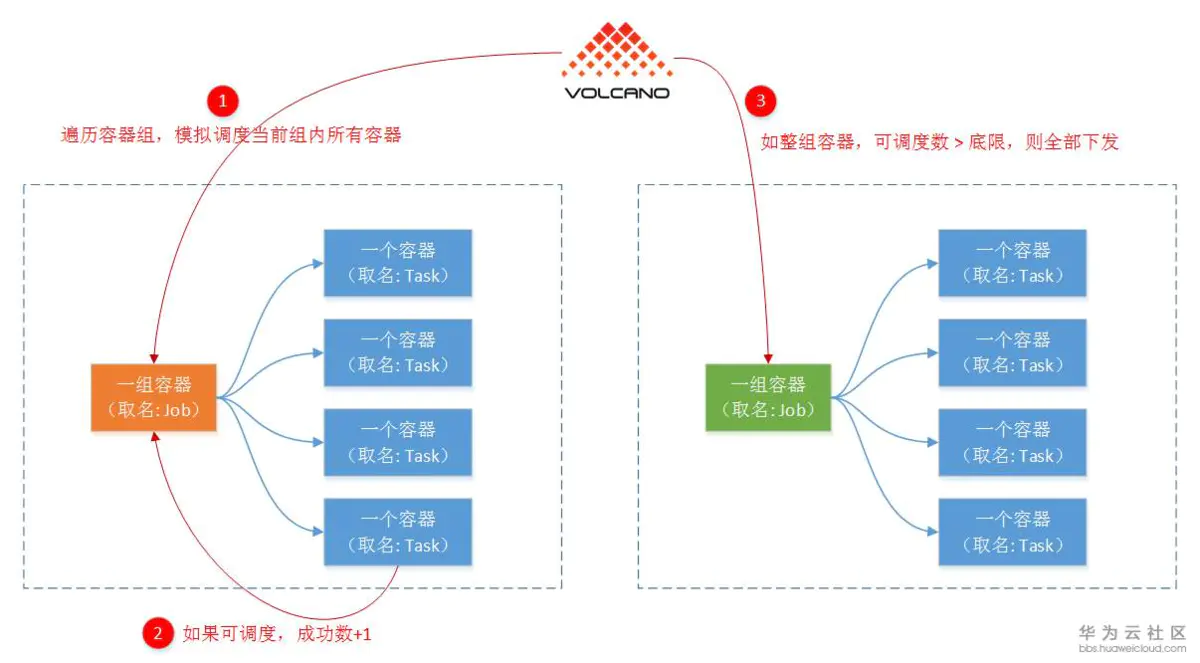
Gang Scheduling
- DRF(dominant resource fairness)
这种调度算法,主要是Yarn和Mesos都有,而K8S没有,需要补齐。概括而言,DRF意为:“谁要的资源少,谁的优先级高”。因为这样可以满足更多的作业,不会因为一个胖业务,饿死大批小业务。注意:这个算法选的也是容器组(比如一次AI训练,或一次大数据计算)。
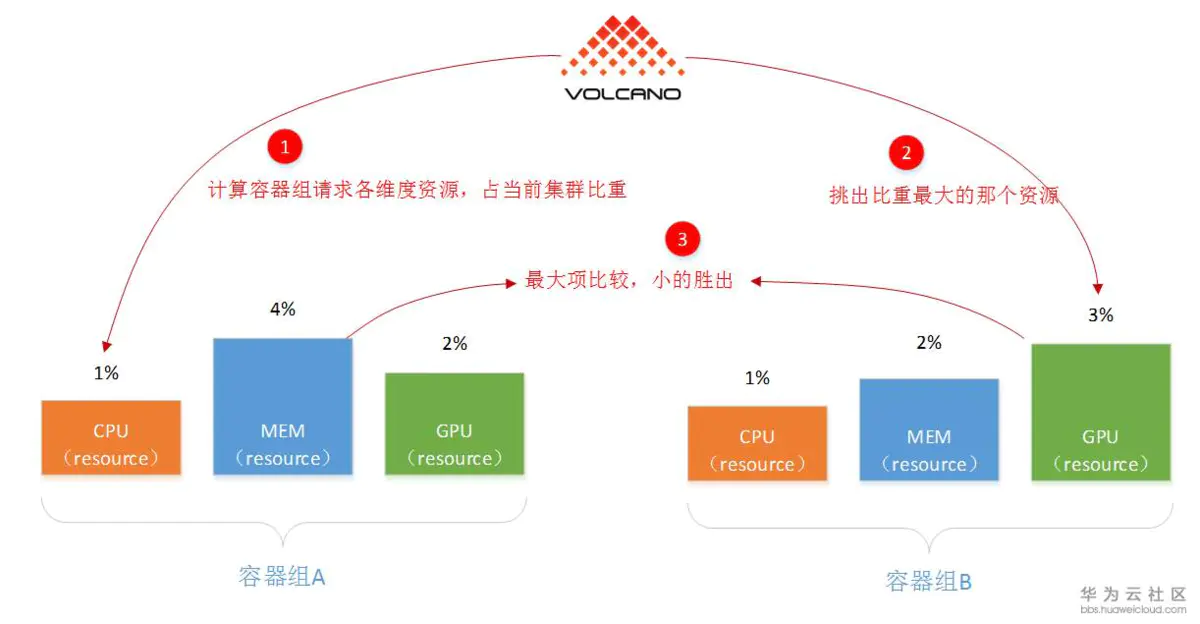
DRF(dominant resource fairness)
- binpack
这种调度算法,目标很简单:尽量先把已有节点填满(尽量不往空白节点投)。具体实现上,binpack就是给各个可以投递的节点打分:“假如放在当前节点后,谁更满,谁的分数就高”。因为这样可以尽量将应用负载靠拢至部分节点,非常有利于K8S集群节点的自动扩缩容功能。注意:这个算法是针对单个容器的。
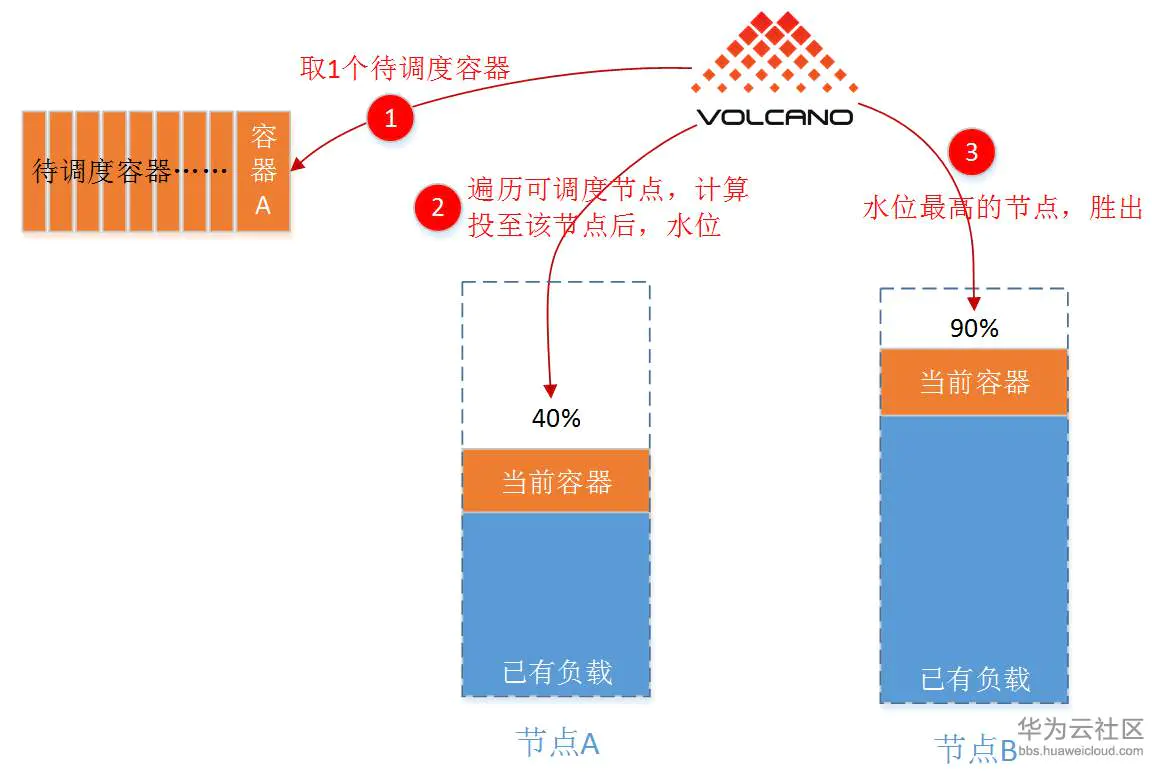
binpack
从下图可以看到,优化前资源碎片率高达43%:

优化前
优化之后,资源碎片率降低到了30%,并且还在持续自动优化:

优化后
后记
资源优化是一个曲折而艰辛的道路,在这个过程中我们付出了很多努力,得到的成果也是非常丰硕的。虽然目前整体65%的资源利用率在很多人看来好像不是很高,主要是因为机器学习任务大多是重型任务,没有足够的小任务把资源碎片消除干净。后续我们也在考虑和运维同学合作,调度一些微服务到 K8s 集群中,来尽可能的填补资源碎片,那时候资源利用率提升到80%以上应该也不是难事。
最后,希望我们的资源优化方案能起到抛砖引玉的作用,当大家遇到类似的问题时,能给大家提供一些解题思路我就心满意足了。