MySQL作为老牌的应用场景广泛的关系型开源数据库,其底层架构是很值得我们学习的,吸收其设计精华,那么我们在平时的方案设计工作中也可以借鉴,如果项目中用的是MySQL,那么就能够把数据库用的更好了,了解了MySQL底层的执行原理,对于调优工作也是有莫大帮助的。
本文我重点讲述MySQL底层架构,涉及到:
- 内存结构:buffer pool、log buffer、change buffer,buffer pool的页淘汰机制是怎样的;
- 磁盘结构:系统表空间、独立表空间、通用表空间、undo表空间、redo log;
- 以及IO相关底层原理、查询SQL执行流程、数据页结构和行结构描述、聚集索引和辅助索引的底层数据组织方式、MVCC多版本并发控制的底层实现原理,以及可重复读、读已提交是怎么通过MVCC实现的。
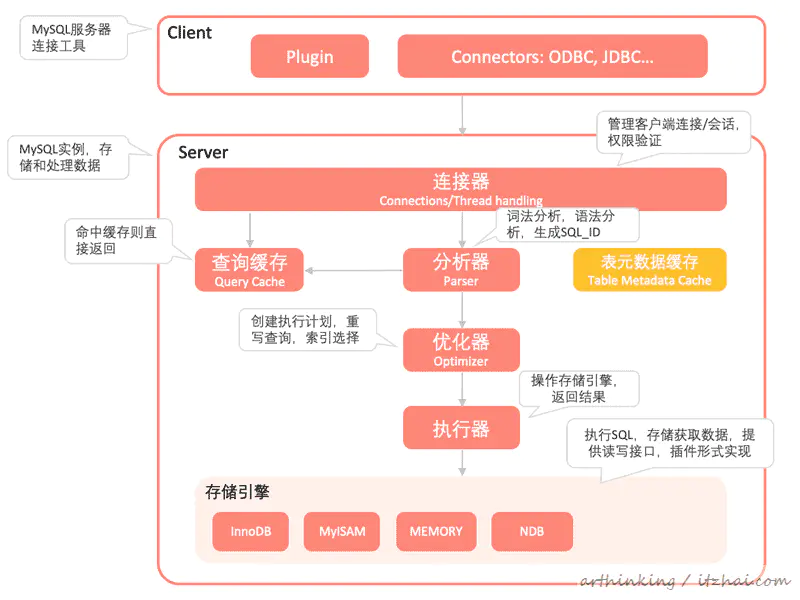
1、MySQL架构
2、查询SQL执行流程
我们执行以下sql:
select * from t_user where user_id=10000;
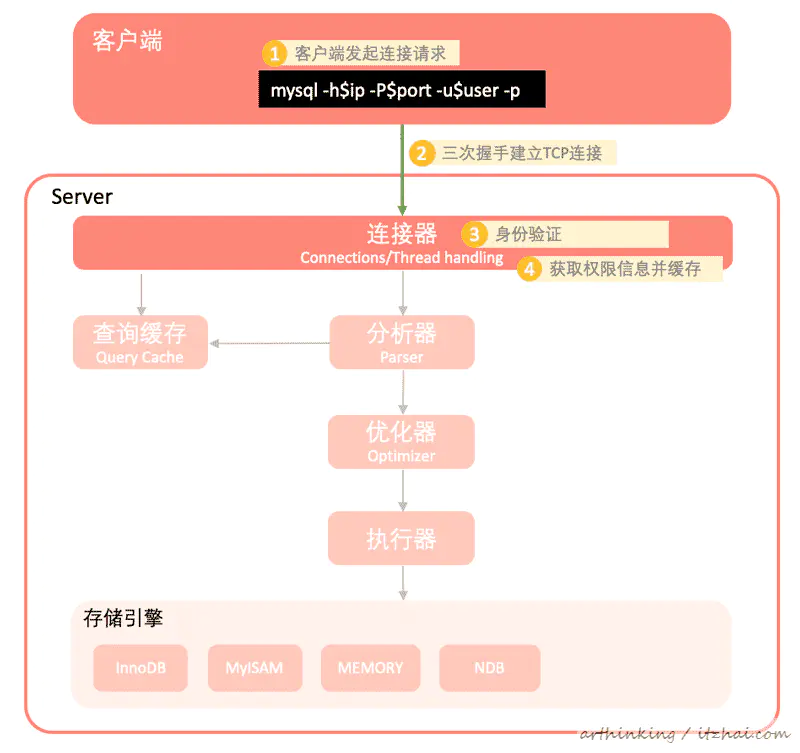
2.1、MySQL客户端与服务器建立连接
如下图,建立过程:
- 客户端通过mysql命令发起连接请求;
- 经过三次握手后与服务端建立TCP连接;
- 连接器接收到请求之后使用用户密码进行身份验证;
- 验证通过之后,获取用户的权限信息缓存起来,该连接后面都是基于该缓存中的权限执行sql;
对于Java应用程序来说,一般会把建立好的连接放入数据库连接池中进行复用,只要这个连接不关闭,就会一直在MySQL服务端保持着,可以通过show processlist命令查看,如下:

注意,这里有个Time,表示这个连接多久没有动静了,上面例子是656秒没有动静,默认地,如果超过8个小时还没有动静,连接器就会自动断开连接,可以通过wait_timeout参数进行控制。
2.2、执行SQL
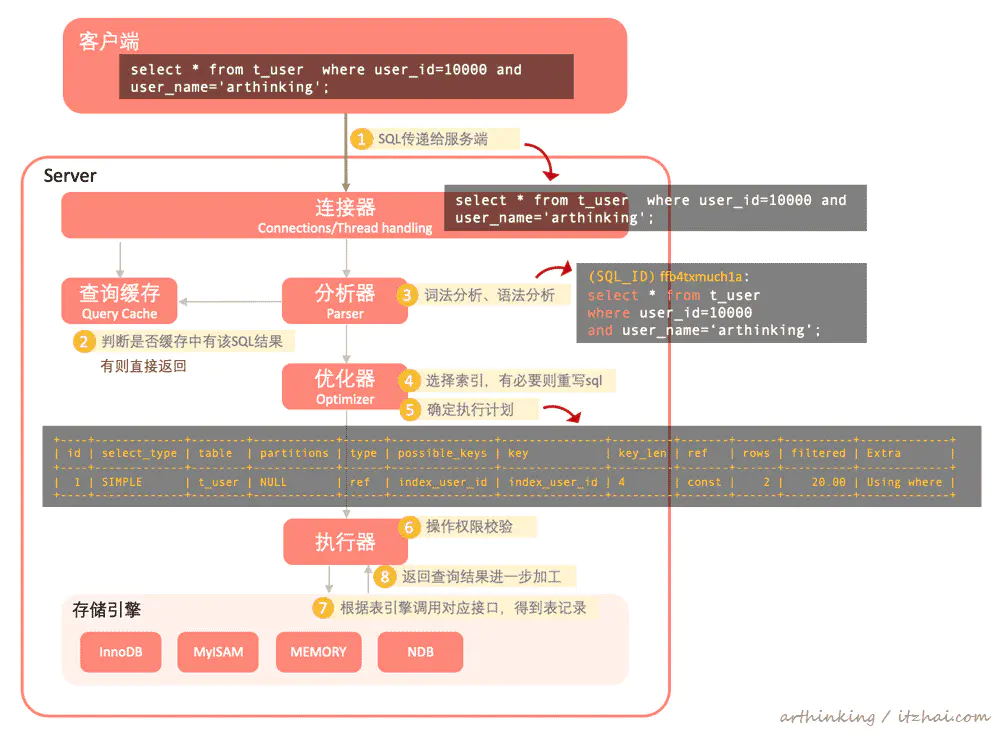
- 服务端接收到客户端的查询sql之后,先尝试从查询缓存中查询该sql是否已经有缓存的结果了,如果有则直接返回结果,如果没有则执行下一步;
- 分析器拿到sql之后会尝试对sql语句进行词法分析和语法分析,校验语法的正确性,通过之后继续往下执行;
- 优化器拿到分析器的sql之后,开始继续解析sql,判断到需要走什么索引,根据实际情况重写sql,最终生成执行计划;
- 执行器根据执行计划执行sql,执行之前会先进行操作权限校验;然后根据表存储引擎调用对饮接口进行查询数据,这里的扫描行数就是指的接口返回的记录数,执行器拿到返回记录之后进一步加工,如本例子:
- 执行器拿到select * from t_user where user_id=10000的所有记录,在依次判断user_name是不是等于”arthinking”,获取到匹配的记录。
3、InnoDB引擎架构
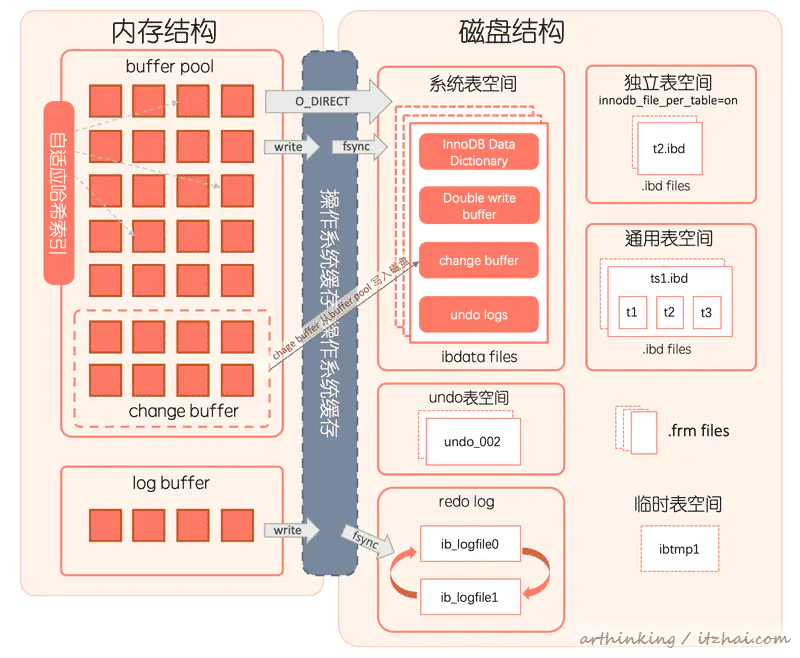
其实内存中的结构不太好直接观察到,不过磁盘的还是可以看到的,我们找到磁盘中MySQL的数据文件夹看看:
cd innodb_data_home_dir 查看MySQL 数据目录:
1 | |- ib_buffer_pool // 保存缓冲池中页面的表空间ID和页面ID,用于重启恢复缓冲池 |
接下来我们逐一来介绍。
3.1、buffer pool

buffer pool(缓冲池)是主内存中的一个区域,在InnoDB访问表数据和索引数据的时候,会顺便把对应的数据页缓存到缓冲池中。如果直接从缓冲池中直接读取数据将会加快处理速度。在专用服务器上,通常将80%左右的物理内存分配给缓冲池。
为了提高缓存管理效率,缓冲池把页面链接为列表,使用改进版的LRU算法将很少使用的数据从缓存中老化淘汰掉。
3.1.1、缓冲池LRU算法
通过使用改进版的LRU算法来管理缓冲池列表。
当需要把新页面存储到缓冲池中的时候,将淘汰最近最少使用的页面,并将新页面添加到旧子列表的头部。
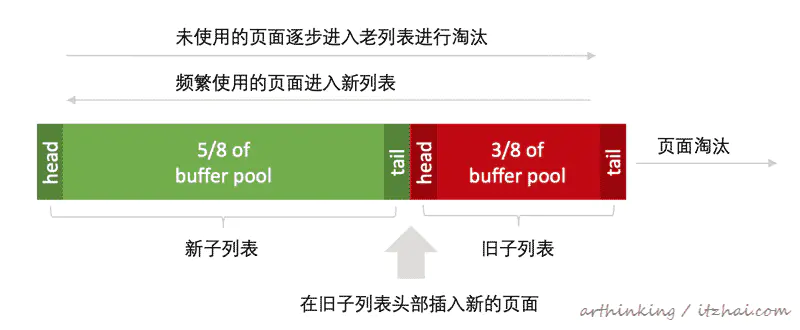
该算法运行方式:
- 默认 3/8缓冲池用于旧子列表;
- 当新页面如缓冲池时,首先将其插入旧子列表头部;
- 重复访问旧子列表的页面,将使其移动至新子列表的头部;
- 随着数据库的运行,页面逐步移至列表尾部,缓冲池中未被方位的页面最终将被老化淘汰。
相关优化参数:
- innodb_old_blocks_pct:控制LRU列表中旧子列表的百分比,默认是37,也就是3/8,可选范围为5~95;
- innodb_old_blocks_time :指定第一次访问页面后的时间窗口,该时间窗口内访问页面不会使其移动到LRU列表的最前面。默认是1000,也就是1秒。
innodb_old_blocks_time很重要,有了这1秒,对于全表扫描,由于是顺序扫描的,一般同一个数据页的数据都是在一秒内访问完成的,不会升级到新子列表中,一直在旧子列表淘汰数据,所以不会影响到新子列表的缓存。
3.1.2、关于磁盘IO的方式
O_DIRECT是innodb_flush_method参数的一个可选值。
这里先介绍下和数据库性能密切相关的文件IO操作方法
3.1.2.1、文件IO操作方法
数据库系统是基于文件系统的,其性能和设备读写的机制有密切的关系。
open:打开文件
1 | int open(const char *pathname, int flags); |
系统调用Open会为该进程一个文件描述符fd,常用的flags如下:
- O_WRONLY:表示我们以”写”的方式打开,告诉内核我们需要向文件中写入数据;
- O_DSYNC:每次write都等待物理I/O完成,但是如果写操作不影响读取刚写入的数据,则不等待文件属性更新;
- O_SYNC:每次write都等到物理I/O完成,包括write引起的文件属性的更新;
- O_DIRECT:执行磁盘IO时绕过缓冲区高速缓存(内核缓冲区),从用户空间直接将数据传递到文件或磁盘设备,称为直接IO(direct IO)。因为没有了OS cache,所以会O_DIRECT降低文件的顺序读写的效率。
**write:写文件
1 | ssize_t write(int fd, const void *buf, size_t count); |
使用open打开文件获取到文件描述符之后,可以调用write函数来写文件,具体表现根据open函数参数的不同而不同弄。
fsync & fdatasync:刷新文件
1 | #include |
- fdatasync:操作完write之后,我们可以调用fdatasync将文件数据块flush到磁盘,只要fdatasync返回成功,则可以认为数据已经写到磁盘了;
- fsync:与O_SYNC参数类似,fsync还会更新文件metadata到磁盘;
- sync:sync只是将修改过的块缓冲区写入队列,然后就返回,不等实际写磁盘操作完成;
为了保证文件更新成功持久化到硬盘,除了调用write方法,还需要调用fsync。
大致交互流程如下图:
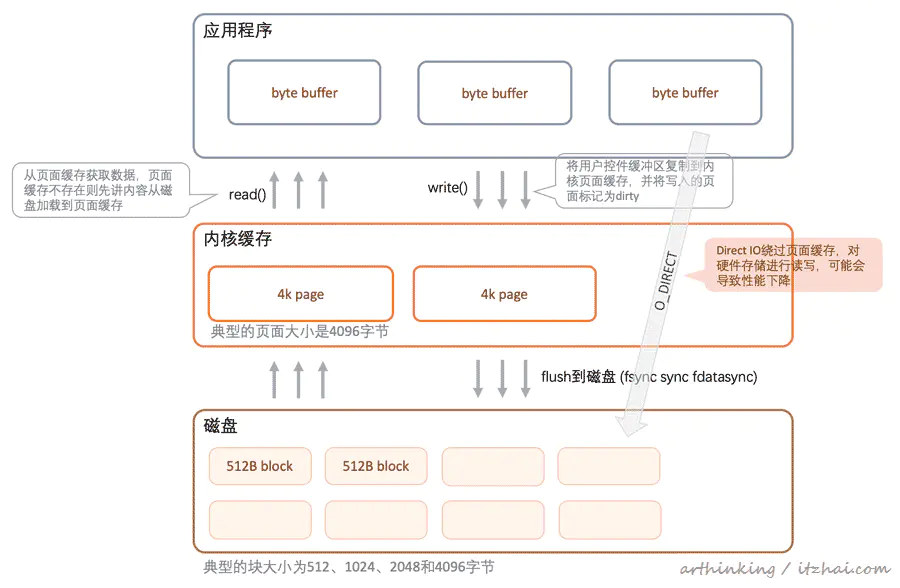
fsync性能问题:除了刷脏页到磁盘,fsync还会同步文件metadata,而文件数据和metadata通常存放在磁盘不同地方,所以fsync至少需要两次IO操作。
对fsync性能的优化建议:由于以上性能问题,如果能够减少metadata的更新,那么就可以使用fdatasync了。因此需要确保文件的尺寸在write前后没有发生变化。为此,可以创建固定大小的文件进行写,写完则开启新的文件继续写。
3.1.2.2、innodb_flush_method
innodb_flush_method定义用于将数据刷新到InnoDB数据文件和日志文件的方法,这可能会影响I/O吞吐量。
以下是具体参数说明:

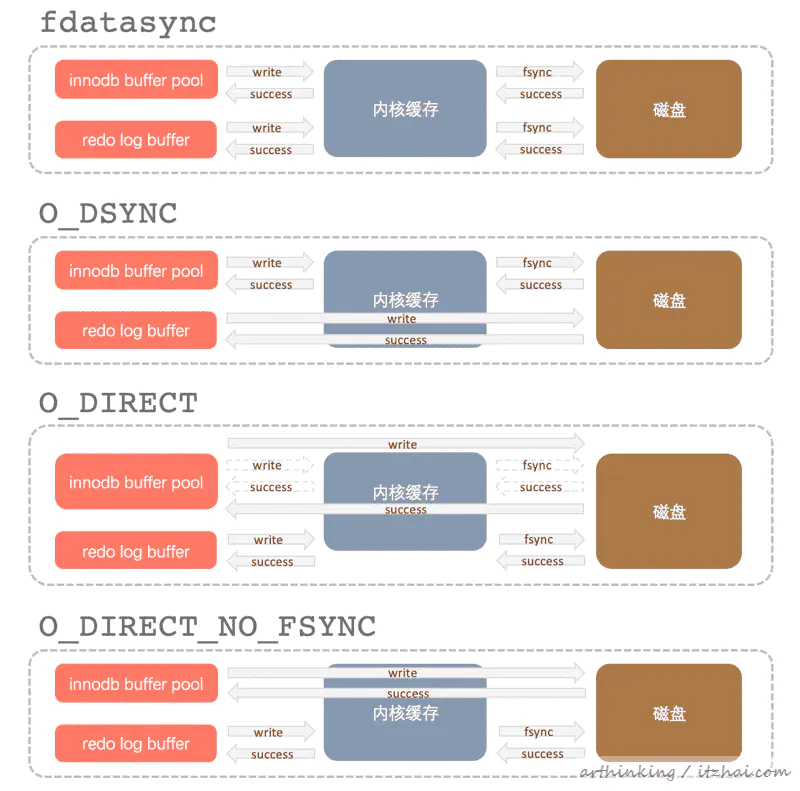
比较常用的是这三种:
fsync
默认值,使用fsync()系统调用来flush数据文件和日志文件到磁盘;
O_DSYNC
由于open函数的O_DSYNC参数在许多Unix系统上都存中问题,因此InnoDB不直接使用O_DSYNC。
InnoDB用于O_SYNC 打开和刷新日志文件,fsync()刷新数据文件。
表现为:写日志操作是在write函数完成,数据文件写入是通过fsync()系统调用来完成;
O_DIRECT
使用O_DIRECT (在Solaris上对应为directio())打开数据文件,并用于fsync()刷新数据文件和日志文件。此选项在某些GNU/Linux版本,FreeBSD和Solaris上可用。
表现为:数据文件写入直接从buffer pool到磁盘,不经过操作系统缓冲,日志还是需要经过操作系统缓存;
O_DIRECT_NO_FSYNC
在刷新I/O期间InnoDB使用O_DIRECT,并且每次write操作后跳过fsync()系统调用。
此设置适用于某些类型的文件系统,但不适用于其他类型的文件系统。例如,它不适用于XFS。如果不确定所使用的文件系统是否需要fsync()(例如保留所有文件元数据),请改用O_DIRECT。
为什么使用了O_DIRECT配置后还需要调用fsync()?
参考MySQL的这个bug:Innodb calls fsync for writes with innodb_flush_method=O_DIRECT
Domas进行的一些测试表明,如果没有fsync,某些文件系统(XFS)不会同步元数据。如果元数据会更改,那么您仍然需要使用fsync(或O_SYNC来打开文件)。
例如,如果在启用O_DIRECT的情况下增大文件大小,它仍将写入文件的新部分,但是由于元数据不能反映文件的新大小,因此如果此刻系统发生崩溃,文件尾部可能会丢失。
为此:当重要的元数据发生更改时,请继续使用fsync或除O_DIRECT之外,也可以选择使用O_SYNC。
MySQL从v5.6.7起提供了O_DIRECT_NO_FSYNC选项来解决此类问题。
3.4、Log Buffer
log buffer(日志缓冲区)用于保存要写入磁盘上的log file(日志文件)的数据。日志缓存区的内容会定期刷新到磁盘。
日志缓冲区大小由innodb_log_buffer_size变量定义 。默认大小为16MB。较大的日志缓冲区可以让大型事务在提交之前无需将redo log写入磁盘。
如果您有更新,插入或者删除多行的事务,尝试增大日志缓冲区的大小可以节省磁盘I/O。
3.4.1、配置参数
innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit 变量控制如何将日志缓冲区的内容写入并刷新到磁盘。
该参数控制是否严格存储ACID还是尝试获取更高的性能,可以通过该参数获取更好的性能,但是会导致在系统崩溃的过程中导致数据丢失。
可选参数:
- 0,事务提交之后,日志只记录到log buffer中,每秒写一次日志到缓存并刷新到磁盘,尚未刷新的日志可能会丢失;
- 1,要完全符合ACID,必须使用该值,表示日志在每次事务提交时写入缓存并刷新到磁盘;
- 2,每次事务提交之后,日志写到page cache,每秒刷一次到磁盘,尚未刷新的日志可能会丢失;
innodb_flush_log_at_timeout
innodb_flush_log_at_timeout 变量控制日志刷新频率。可让您将日志刷新频率设置为N秒(其中N为1 … 2700,默认值为1)
为了保证数据不丢失,请执行以下操作:
如果启用了binlog,则设置:sync_binlog=1;
1 | innodb\_flush\_log\_at\_trx_commit=1; |